我对六西格玛系统理解
一直对六西格玛质量管理一知半解,最近花了点时间,与群内的几位朋友聊了聊。自己又琢磨了一下,感觉对六西格玛的整个过程有所了解了,总结后分享给大家,一起来看一下我的理解是否正确。
什么是六西格玛
讲到六西格玛,很多大咖都以质量管理、质控的历史演变等为开篇,例如讲摩托罗拉,IBM等公司在这方面的应用等。我对这些到不是特别关心,不过有一些数字还是比较吸引我的,我们一起看一下的这个例子。
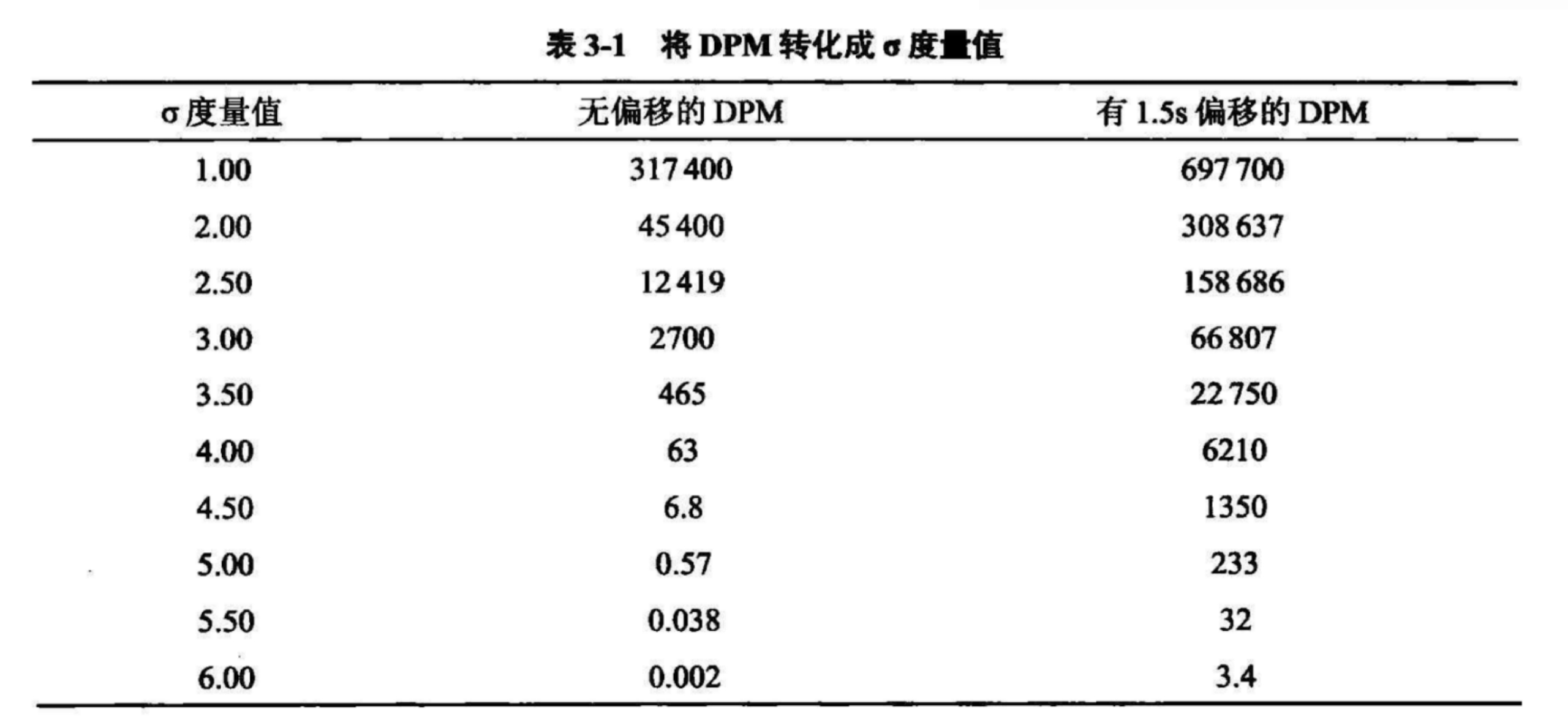
如果你的系统能达到6σ,你的错误率应该在百万分之3.4,是不是感觉很牛。
那么到底什么是六西格玛呢?我个人通俗的理解,就是在上下规格线内,包含的标准差的个数,当然前提是样本属于正态分布。
西格玛可以理解为标准差,我们日常L-J质控图,在-3s到3s之间标注数据点,所以对标准差、变异系数这些指标应该很熟悉。几个西格玛的意思,就是统计学里正态分布的z值,我们可以把这个正态分布曲线,划分为-6s到+6s,那么6σ就代表你的错误率仅有超出-6s和+6s范围的部分,即百万分之0.002至3.4。
那么上面的这个百万分之0.002的错误率是如何计算来的呢?在考虑有偏倚的情况下,错误率为什么会增加到3.4呢?网络上没有找到这方面的详细介绍和推算过程,今天我就给大家演示一下,在excel中,把这个过程都推理出来,也算是对上面的数据的一种验证,我相信这一过程非常有助于理解六西格玛,揭开西格玛度量值的统计学本质。
首先我们打开excel设计一个正态分布,我们设置不同的正态分布的z值,标准叫法应该是σ度量值。
当z值取1,那么从负无穷到1之间对应的概率p,可以用NORM.S.DIST来计算,然后减去0.5的概率,剩下的就是0-1之间的概率,再把这个概率乘以2,也就是在±1之间,得到的正确的概率为68%。
以此类推
当z值取2,在±2之间,得到的正确的概率为95%。
当z值取3,在±3之间,得到的正确的概率为99.7%。
以此类推,z值取6,在±6之间,得到的正确的概率为99.9999998%,错误率也就是超出±6的概率为1-99.9999998%,在换算成ppm就得到了0.002,即前面提到的百万分之0.002。
以上是比较理想的情况,根据摩托罗拉等公司的探索发现,实际上过程平均数偏离中心值的可能性非常高,综合考虑后,这个偏离值一般定为±1.5s。为了方便我推算,我把这个偏倚量,设置为正偏倚1.5s。
那么z值就由,原来的1,变为-0.5,那么从负无穷大到-0.5之间对应的概率p,可以用NORM.S.DIST来计算,得到的正确的概率为30.85%,错误率则为69%(左侧还有部分也应该包含在内)。
原来的2,变为0.5,得到的正确的概率为69%,错误率为30%。
原来的3,变为1.5,得到的正确的概率为93.2%,错误率为6.6%。
以此类推,6σ也变为了4.5,得到的正确的概率为99.99966%,错误率为0.0034%,换算成百万分之几的错误率,就得到了3.4个/百万(左侧超出-6s的p几乎为0,所以忽略)。
这就是σ的统计学验算过程。
不难发现,经过验算,您可以感觉到从3σ到6σ的过程,是不成线性的。换个说法,从5σ提升到6σ付出的努力要远远大于从3σ提升到4σ的努力,这个问题,我们后面继续讨论。
在医学检验中的应用
从上面的例子,我们可以看出,σ的值越大,就代表正确的概率越高,出错的概率越低,那么,我们如何把上面的理论转化为医学检验的实际应用呢?
1、按照上面的6σ质量水平,我们可以估算检验过程产生的一些问题,例如检验结果解审、检验超时,各种登记错误情况等等。
下面我用我科室,接收标本情况,做个例子,对其进行一下评估。
我咨询了我科室标本处理组小伙伴,查询2021年度的标本不合格率为0.063%换算成DPM为0.00063*100w=630,通过图表初步观察,这个σ度量值应该在4.5-5之间,还达不到5σ,当然具体的数值可以用excel反推算得到,这里我就不算了。
提到质量,可能还要谈到PDCA和DMAIC质量管理模型。所以上面这个标本接受的例子,还要继续探讨,就涉及标本具体的错误类型、错误原因,错误标本涉及工作组等,这里我就不展示了。
不过这里我简单说一下我的理解,如果真正的提高质量,由3σ到4σ可能比较容易,但想达到6σ,检验科智能化程度应该是一个瓶颈,一些指标如果不借助计算机是无法计算的,更无法确保准确了。前几天回顾了北京协和医院尚雪松老师,在去年3月份,讲的六西格玛的实践应用,其中谈及自动化质控,同时也表示对于大型医院的智能化管理是非常重要。对于实验室质量管理方面,涉及到的问题特别多,经验有限,也不展开介绍了。
在检验分析测量过程的应用
从前面基础部分的介绍,σ的值的含义其实是,在规定的范围内,可以容纳正态分布的标准差的个数。这一概念的理解非常重要。
那么具体的公式如下:

通过这个公式,也不难理解,总允许误差在减去偏倚后,包含几个变异,就代表几个σ。
为了更加清晰的展示一下他们之间的对应关系。
我们可以通过这个模型看出:
当Bias越小,在TEa的范围内,容纳的标准差越多,所以σ的值的越大。
当cv越小,在TEa的范围内,容纳的标准差越多,所以σ的值越大。
理解了这个公式,那我们再看看,其中的具体项的选取。
TEa的来源可以是基于生物学变异、美国CLIA、或者我国的行业标准WS/T等,值得注意的一点就是,这个TEa的来源对σ的计算结果影响还是非常大的,所以输出结果时,标注总误差来源是很有必要的。
Bias来源可以是室间质评、也可以通过实验室比对的组均值得到。
Cv就是平时质控就可以推导出来了,为了更加有效的评估,这里用多个月的累计的cv值显得更加合理。
如果您的实验室条件允许,也可以对每个月的质控数据的basi和cv,进行σ的计算并监控,这样就可以对我们的检验系统进行简单、方便、持续的评价。
有了这样一个西格玛的结果,我们如何判断结果的好坏呢?
我们可以把σ度量值结果从小到大依次分为:
<3欠佳
3-4临界
4-5良好,航空行李处理4000DPM
5-6优秀
>6世界一流,航空安全旅客死亡事故0.43DPM
在选择质量控制方法的应用
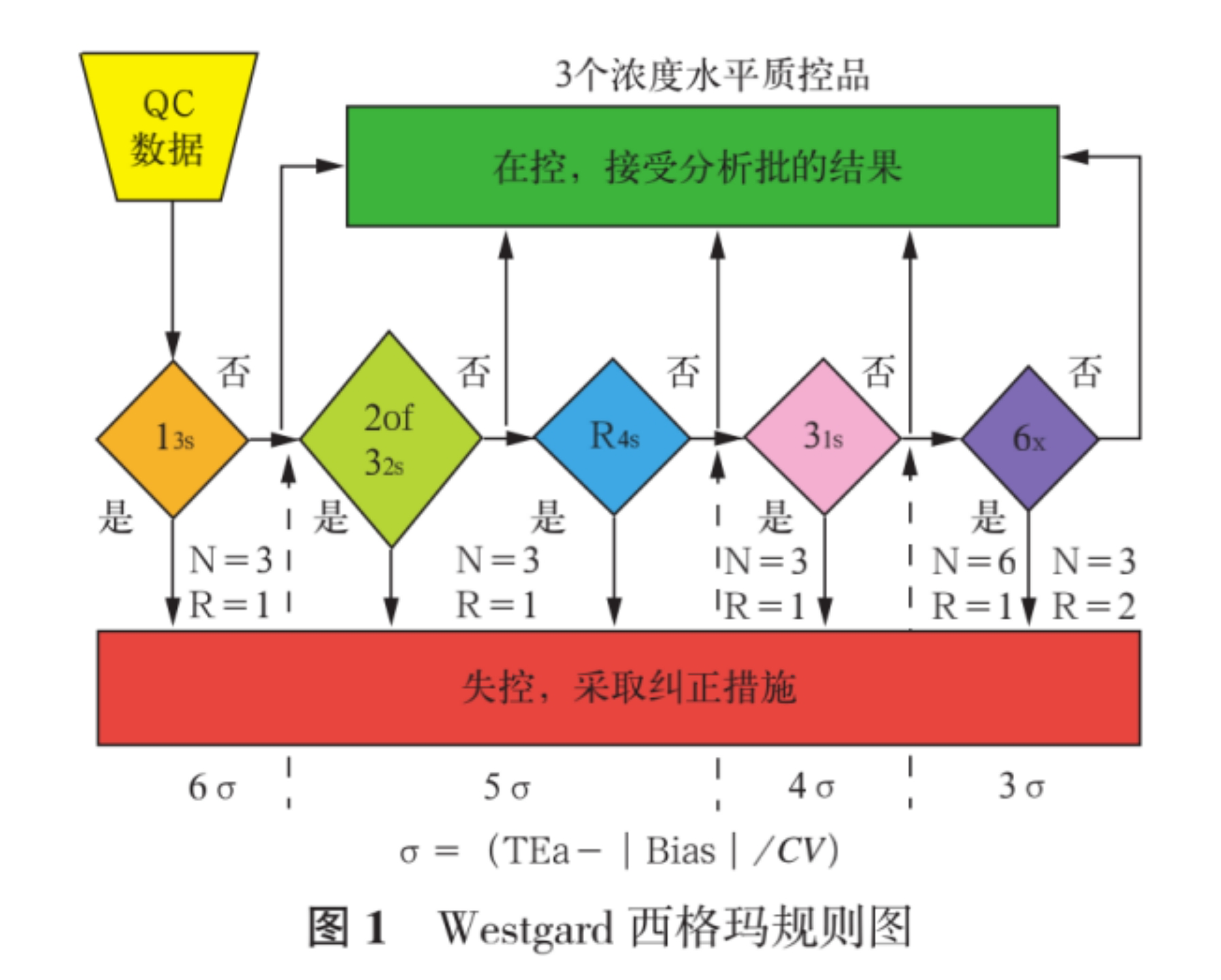
质控规则有很多种,例如:13s、22s、R4s等等,每一次的触发都可以看做一次警报,如果警报是真的还好,如果是假警报,久而久之会改变人们对质控警报的行为方式。这个就好比小时候那个故事,狼来了。过多的质控规则不仅仅会造成资源的浪费,更重要的是人们一但对警报产生了免疫,那将是完全恶化的质量控制过程。
所以根据不同的项目选择适当的质控规则是非常有必要的,自定义的项目的质控规则,可以根据σ的度量值来进行。
具体分析,寻找分析性能不佳的原因
通过计算QGI来查找分析性能不佳的原因,进行相应的改进措施。
QGI = bias/(1.5*CV),当σ>6时无需改进。如果σ<6,可根据OGI的值,判断导致方法学性能不好的主要原因。
QGI<0.8,则精密度不佳是主要原因。
0.8<QGI<1.2,是精密度和准确度共同原因。
QGI>1.2,则主要由准确度不佳导致,需要改进准确度。
方法决定图和操作过程规范图
为了更加方便直观的根据偏倚和不精密度,来判断西格玛的度量值,我们可以看到如图,面积最大的上半部分为不可接受、然后依次向左,良好、优秀、世界级。这样就可以很方便的根据您的偏倚和不精密度的交叉点,来判断σ的度量值。
还有操作过程图,分别显示了不同的质控规则组合的情况下的预期性能。
最后做一下总结
当然,六西格玛系统远没有我讲的这么简单,在实际工作中的情况更为复杂,也会遇到非常多的问题。
本次内容仅仅算是我对六西格玛系统的入门介绍,后续还希望与大家有更多的交流,不知道在不久的将来,这套6σ管理体系是否能像今天Levey-Jennings质控一样普及呢?好了,今天就到这里,制作不易,点颗小红心呗,好朋友们88啦。
感谢&参考:
沈阳医学院附属中心医院 黎明新
大连医科大学附属第二医院 王婧涵
邳州市中医院检验科 卢文雅
Westgard QC公司 Sten Westgard
浙江大学医学院附属邵逸夫医院 张钧
北京协和医院 尚雪松
临床检验6σ质量设计与控制 王治国主编
Westgard Sigma多规则 冯仁丰